User Classification With Keystroke Biometrics And A Recurrent Neural Network
For this project we will use a Flask application to create a dataset of keystroke dynamics from different users. Then we will use Keras to model a recurrent neural network, and train the model using keystroke dynamics as features and usernames as labels. After training, we will evaluate the model by predicting the user that is currently typing.
Clone The Git Repository
Begin by cloning the git repository for this project:
$ git clone https://github.com/username/ml-typing
$ cd ml-typing
Set Up Your Development Environment
Before we run the Flask application, let's create a virtual environment for this project, activate it, and install the packages: flask, numpy, flask-sqlalchemy, and tensorflow
$ python3 -m venv venv
$ source venv/bin/activate
$ pip install flask numpy flask-sqlalchemy tensorflow
- Flask is the web framework we will use to handle requests from the browser.
- Numpy is a mathematics library that we will use to perform matrix operations on arrays.
- SQLAlchemy is an ORM that will simplify SQL queries by mapping our database to python objects.
- Tensorflow is a mathematics and machine learning library that we will use to create a neural network.
More detailed information about environments and packages (including commands for Windows), can be found here: Virtual Environments and Packages
Run The Flask Application
After we've set up our virtual environment we are ready to run the Flask application using the following command:
$ python typing_analysis_flask.py
This command will execute the if __name__ == '__main__' block of code in typing_analysis_flask.py
if __name__ == '__main__':
db.create_all()
app.run()
When db.create_all() is called, SQLAlchemy creates a database schema that has a
table mapped to each db.model subclass. Here, we are creating schema for one table
with three columns mapped to our TypingData class:
class TypingData(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(128))
json_str = db.Column(db.String(4096))
Then SQLAlchemy will use the schema to create a SQLite database file in the location set
as the SQLALCHEMY_DATABASE_URI. For this project it will be located at
./typing_data.sqlite3
After the database is created, the app.run() command starts the Flask
development server at http://127.0.0.1:5000.
Create A Keystroke Dataset
Open http://127.0.0.1:5000 in your browser while the flask server is running to begin collecting keystroke data that will be used for training the model.
On this page, you are given a random excerpt from a public domain book, and a textarea
to type in. Keystroke data will be logged in your browser using javascript as you type
in the textarea. You can inspect the console to see the data that is logged.

After typing the excerpt into the textarea, you can name the user and click "Save Keystroke Data"
to save the data in the database. If there is only one user, you can still complete this project by
creating three different usernames, and type differently for each of them: left hand only,
right hand only, and both hands.

Features
Three features are used as inputs into the neural network:
- The first feature is a 1 or 0 for a key-down or key-up event
- The second feature is the Javascript
keyCode - The third feature is the milliseconds since the previous event
As a user is typing in the textarea, the keystroke data is stored in a
Javascript array with dimensions [num_of_events, 3].
For example, the following array has the dimensions [24, 3] because there are 24 keystroke events, and each event has three features.
[[1, 16, 0],
[0, 16, 131],
[1, 65, 92],
[0, 65, 25],
[1, 84, 90],
[0, 84, 40],
[1, 32, 88],
[0, 32, 70],
[1, 76, 33],
[1, 65, 130],
[0, 76, 80],
[0, 65, 54],
[1, 83, 55],
[0, 83, 76],
[1, 84, 123],
[0, 84, 102],
[1, 32, 4],
[0, 32, 143],
[1, 83, 5],
[0, 83, 80],
[1, 72, 111],
[0, 72, 113],
[1, 69, 24],
[1, 32, 96]]
When the "Save" button is clicked, the browser makes a POST request to the Flask app,
and the app saves the keystroke data as a JSON string in the TypingData table that was created earlier.
Labels
When a sequence of keystroke data is saved into the database, the username that was submitted is also saved so that it can be used as a label. The usernames are saved as strings, but they will be mapped to integers before training the model.
Preprocessing Keystroke Data
Before we train a neural network with our keystroke data, we will preprocess the data so that it is more consistent. Here are a few of the steps we can take that will make the data more consistent and improve the performance of our neural network:
- Batching sequences of keyboard events to make the number of events uniform
- Mapping labels to integers using a
TextVectorizationlayer - Normalizing Time Data
Batching Sequences Of Keystroke Events
For our neural network to be most efficient, we want all the inputs to have the same shape. Right now, the shape of our keystroke data is (number_of_events, 3) so the length depends on how many keys were typed by a user. To account for this we will batch our keystroke events into sequences of length 10.
Using the example above with 24 keystroke events, we would batch the data with list comprehension into 2 lists with 10 events each, and remove the remaining 4 events:
>>> np.array(json_obj).shape
(24, 3)
>>> key_seqs = [np.array(json_obj[x:x+10])
for x in range(0, len(json_obj), 10)]
>>> np.array(key_seqs[:-1]).shape
(2, 10, 3)
Mapping Labels To Integers
The output of the neural network will be an array with a length equal to the number of usernames in the database. Each element in the array is a number that represents the probability that the keystroke input came from the username mapped to the index location of the element.
Because of this, we will use a TextVectorization layer to map usernames to indices.
For example if we have the following list of usernames and keystroke events:

Then after batching the keystroke events into sequences of 10, we will have 12 inputs: 4 from Michael, 3 from Terry, and 5 from John. Here is what the corresponding labels would look like:
>>> x.shape
(12, 10, 3)
>>> y
['Michael Palin' 'Michael Palin' 'Michael Palin' 'Michael Palin'
'Terry Gilliam' 'Terry Gilliam' 'Terry Gilliam' 'John Cleese'
'John Cleese' 'John Cleese' 'John Cleese' 'John Cleese']
Next we would adapt our labels to the TextVectorization layer, and create a
vocabulary that is a list of unique usernames so that each username is represented by an index location.
For example John is at index location 0, Michael is at index location 1, and Terry is at index location 2.
>>> vectorize_layer = keras.layers.TextVectorization(
output_mode='int', split=None)
>>> vectorize_layer.adapt(y)
>>> vectorize_layer.get_vocabulary(include_special_tokens=False)
['john cleese', 'michael palin', 'terry gilliam']
Then we will use the vocabulary to encode our labels into a tensor of index locations:
>>> vectorize_layer(y) - 2
tf.Tensor([1 1 1 1 2 2 2 0 0 0 0 0], shape=(12,), dtype=int64)
Normalizing Time Data
The millisecond values in our dataset can be much higher than the other features, and we don't want them to be weighted more heavily by default, so normalizing the millisecond column will make our data more consistent.
For this process we will use a Keras Normalization layer. The Normalization
layer will convert the mean of the millisecond column to 0, and the standard deviation to 1. To do this, the layer will
find the mean and variance for the millisecond column, and normalize each data point
using the following calculation:
millisecondsnormalized = (milliseconds - mean) / sqrt(variance)
For the example dataset above, with 24 events, let's look at the mean and variance.
>>> normalizer.mean.numpy()
[73.541664]
>>> normalizer.variance.numpy()
[1758.4984]
Then we can plot the distribution before and after normalization. From the plots we can see that normalization changed the domain and range of the distribution, but the shape has not changed.


Model A Recurrent Neural Network
Now that we've defined the shape of the inputs and outputs for our neural network,
we will create a Keras Sequential model. In a Sequential model,
data is passed sequentially from the first layer to the last layer. Therefore the input shape
of the first layer should match our inputs, and the output shape of the last layer should
match our outputs.
model = keras.Sequential([
keras.layers.LSTM(32, input_shape=(10, 3)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dense(len(vocab))
])
The first layer of the model will accept inputs with shape of (10, 3) because we have 10 events per batch and 3 features per event. We will use a Long Short Term Memory (LSTM) layer as the first layer because our keystroke data is a time series, so it should be processed by a recurrent neural network layer.
The output from the last layer in the model will be an array that has the same length as
our TextVectorization layer's vocabulary. Each element in the array is a number
representing the probability that the keystroke input came from the username mapped
to the index location of the element.
For example, the highest value in the following array is at index location
[ 5.3888392 -9.3719635 1.3796585 ]
And our example vocabulary has John at index location
['john cleese', 'michael palin', 'terry gilliam']
So that output can be interpreted as a prediction that the input keystroke data
was typed by the user 'john cleese'.
>>> model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 32) 4608
dense (Dense) (None, 128) 4224
dense_1 (Dense) (None, 32) 4128
dense_2 (Dense) (None, 3) 99
=================================================================
Total params: 13,059
Trainable params: 13,059
Non-trainable params: 0
Train The Model
When training the model, we specify a loss function, optimizer, learning rate, and number of epochs that will yield the most accurate predictions. You can adjust these specs to make the model more accurate when training with your dataset.
By default the application will use the Keras SparseCategoricalCrossentropy
loss function. The model will also train for 250 epochs. The graph below shows loss plotted
against the epochs so that you can see the rate of reduction.
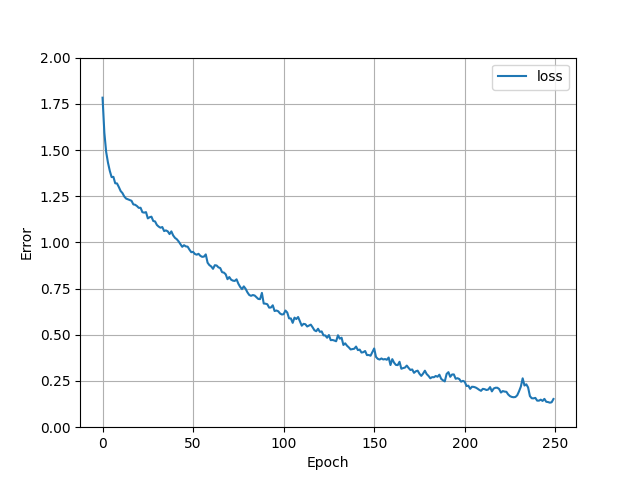
As the loss is reduced, the accuracy of the model's predictions improves. The graph below shows the accuracy plotted against epochs:

The model will be trained when the "Train Model" button is clicked on the page http://127.0.0.1:5000/eval_data. After clicking the button, you can open the terminal window to view the training progress. The model will be saved into ./models so that it can be evaluated later.
Test The Model
The model can be tested by splitting our dataset in two: one dataset for training the model, and
a second dataset for testing the model. One way to do this is with the train_test_spit() funtion from
scikit-learn. The example below will randomly split 20% of the dataset into testing data:
x_train, x_test, y_train, y_test = train_test_split(
x, np.array(y_int), test_size=0.2, random_state=42, shuffle=True
)
Then we can see how accurate the model is at predicting the test data, after it is trained on the training data. This will give us a good estimate of the model's accuracy because the model has not seen the testing data yet. The testing accuracy is usually slightly less than the training accuracy due to overfitting, but the actual value will vary depending on the dataset.
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
Evaluate The Model
Open the page http://127.0.0.1:5000/eval_model, and you will see an interface similar to the keystroke logging page. There is an excerpt of text, a textarea and a submit button. The javascript on this page will log keystroke events that are typed into the textarea.
When the submit button is clicked, the keystroke data is preprocessed the same way it was for training the model. This includes batching events into sequences of 10:
key_seqs = [np.array(json_obj[x:x+10]) for x in range(0, len(json_obj), 10)]
Then the model predicts a label for each sequence of 10 events by returning arrays with a length equal to the length of the vocabulary it was trained with:
>>> predictions = model.predict(np.array(key_seqs[:-1]))
>>> predictions
[[-2.2103875 -0.3140557 -0.30028072]
[ 2.422038 -4.0166388 0.6626577 ]
[ 3.1186361 -3.4882264 0.59489894]
[ 4.520721 -3.872255 -0.02228034]
[-3.8356483 -1.8262669 1.4004098 ]
[ 3.4844098 -4.7236204 0.84627706]
[ 5.329419 -3.9343631 -0.92900115]
[ 4.1051354 -4.1338067 0.03056386]
[ 0.44407105 -3.1287043 0.68481827]
[ 2.9770806 -4.382433 2.1872165 ]
[ 3.1965444 -4.881439 1.157834 ]
[-3.3064384 0.0306097 -0.5215683 ]
[ 4.0153484 -2.720194 -0.6795764 ]
[ 3.9941373 -4.4824133 0.9098247 ]
[ 5.93441 -4.415667 -0.8089384 ]
[ 3.5605664 -3.2192867 0.46833476]
[ 1.0298866 -4.506176 1.9068128 ]
[ 4.033483 -5.7369895 1.2171298 ]
[ 0.7751814 -2.867031 0.5085291 ]
[ 5.014372 -3.7563179 -0.7749958 ]
[ 2.7804117 -4.027991 0.5664353 ]]
Next, the predictions are flattened into a 1D array where each element is the index of the highest value from the prediction:
>>> predictions = [np.argmax(prediction) for prediction in predictions]
>>> predictions
[2, 0, 0, 0, 2, 0, 0, 0, 2, 0, 0, 1, 0, 0, 0, 0, 2, 0, 0, 0, 0]
Then, the most frequent index location in the 1D array is used to predict the user:
>>> index = max(set(predictions), key=predictions.count)
>>> print(index, vocab[index])
0 john cleese
© alchemy.pub 2022 BTC: bc1qxwp3hamkrwp6txtjkavcsnak9dkj46nfm9vmef
- Clone The Git Repository
- Set Up Your Development Environment
- Run The Flask Application
- Create A Keystroke Dataset
- Features
- Labels
- Preprocessing Keystroke Data
- Batching Sequences Of Keystroke Events
- Mapping Labels To Integers
- Normalizing Time Data
- Model A Recurrent Neural Network
- Train The Model
- Test The Model
- Evaluate The Model
